Tips
General
- Simpler networks tend to generalize better. Always start simple and as complexity as needed. Start with one or two hidden layers and one output layer. When adding complexity, first try adding more neurons to the hidden layer before adding another hidden layer.
- Adding neuron layers allows the neural network to express more complicated functions (and thus can lower loss), but also becomes more sensitive to inputs. This can lead it to over fitting the training data, where it performs well with the exact training data input, but starts acting poorly outside of that input. This can be remedied by adding more training data.
- Once you start training, it can be unclear when to stop. When training with a loss, check the network's performance around every 50,000 steps or until the loss doesn't seem to be coming down. When training genetically with a custom loss function, check around every 100 steps. If you are using GeneticTrainingHarness, you can set it to automatically save the best chromosome every X generations. The output file name will have the generation count and computed loss of the best chromosome.
Choosing the Right Trainer
- If you know exactly what the output of the graph should be, use the GradientDescentTrainer.
- If you don't know what the output should be, but you know what a good result is, use the GeneticTrainer.
- If you don't know what the output should be and you can give rewards for good behavior over time, use a reinforcement learning trainer.
Helper Classes
- In the Helpers namespace are a variety of helper classes. INetwork, INetworkController, and NetworkManager all work together. The system allows you to indepenently define consumers of data (controllers) from producers of data (networks). The system is a way to automate stepping of networks at fixed time intervals (manual stepping is also supported) and will automatically batch multiple controller data to a single network evaluation. When the network is implemented by a graph, this is much more efficient than evaluating one controller at a time.
- Leverage the training harnesses to speed up development of training code. They provide support for training in X ms intervals, training over the network, and setup for some genetic training scenarios. See the examples projects for details on how they can be used.
LSTM
- If your graph contains an LSTM neuron layer, it must be stepped to be useful. Stepping is usually done when the inputs change. They must also be periodically reset. You typically reset after a fixed number of steps. If training by gradient descent, an appropriate value to use is the sequence length.
- Training an LSTM with a loss object requires a sequence length. This is the number of pieces of data that make up a "sentence". The trainer will train the LSTM in sequences of this length. Any steps you evaluate past this length may not be as accurate.
Training by Loss (Gradient Descent & Genetic Algorithms)
- The GradientDescentTrainer and GeneticTrainer can train under two modes when using a Loss object: whole dataset and stochastic (see LossTrainingMethodInfo). Whole dataset means to train over the entire dataset with each step in groups of size BatchSize, while stochastic will take a one time random sampling of size BatchSize. In general, training over the whole dataset with a BatchSize of 0 (meaning train against all input in one operation) will converge smoothly over time, while stochastic training will fluctuate as the average loss becomes lower. Training over the whole dataset can introduce bias in the training as the same rows are trained in a strict sequence, leading to underperforming networks. Stochastic avoids this pitfall and thus is the preferred way of training, with a batch size of around 32.
- When training an LSTM, you can provide session indicies that delineate groups of data. The SequenceLength defines how many steps forward should be trained with each training call. For example, training stochastically with a batch size of 32 and a sequence length of 5 will first choose 32 random rows. Then loop 5 times, each time incrementing each of the rows with the next training data. If a session end is reached, the training stops for that row while the others move on.
Gradient Descent Training
- Gradient descent takes longer the more complicated (measured in weight count) the network becomes. Consider using a GeneticTrainer, passing in a Loss if training times become too long.
- Gradients are computed from the output back towards the inputs. Use a GradientStop node to prevent further propagation down the chain. This is one way to control what parts of the graph are being trained.
Genetic Training
- Choosing the right custom loss function when using a SmartEngine.NeuralNetworks.GeneticTrainer GeneticTrainer "GeneticTrainer" is very important. The function should be constructed in a way such that a lower value always means a network performs better than one with a higher loss. If you want a loss function where a higher score is better, simply negate the value before setting the loss. When you have multiple values you want to compare, one technique to try is to first normalize the values between [0..1] and then apply a function to the values. Here are some sample functions shown for 2 variables, but which extend to more than 2 variables. Darker values are closer to 0.
X + Y X * Y (1 + X)*(1 + Y) (e^X + e^Y) 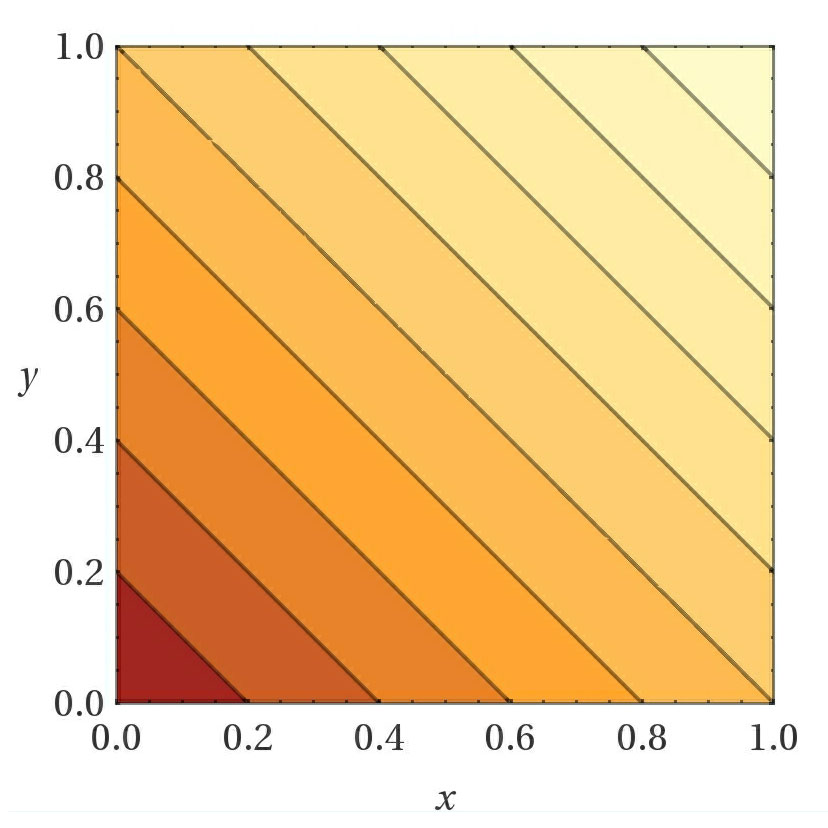
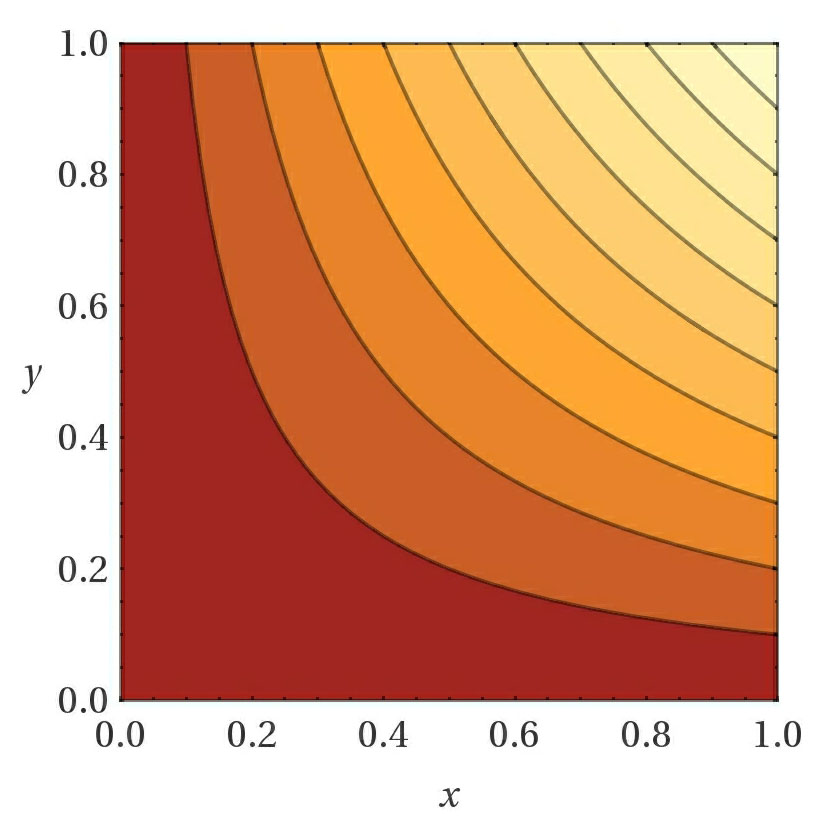
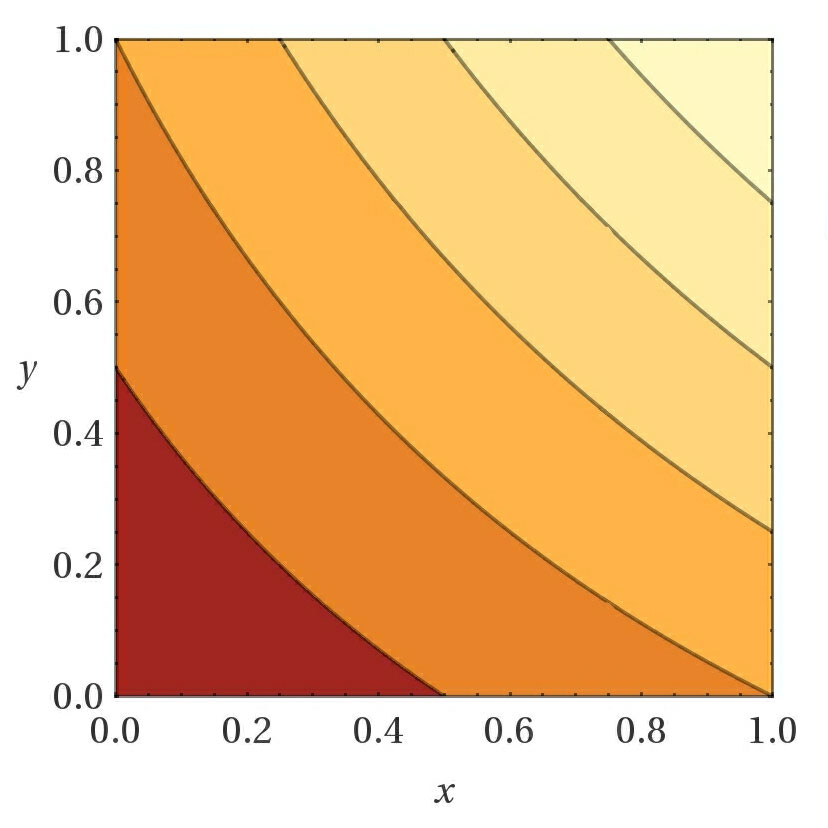
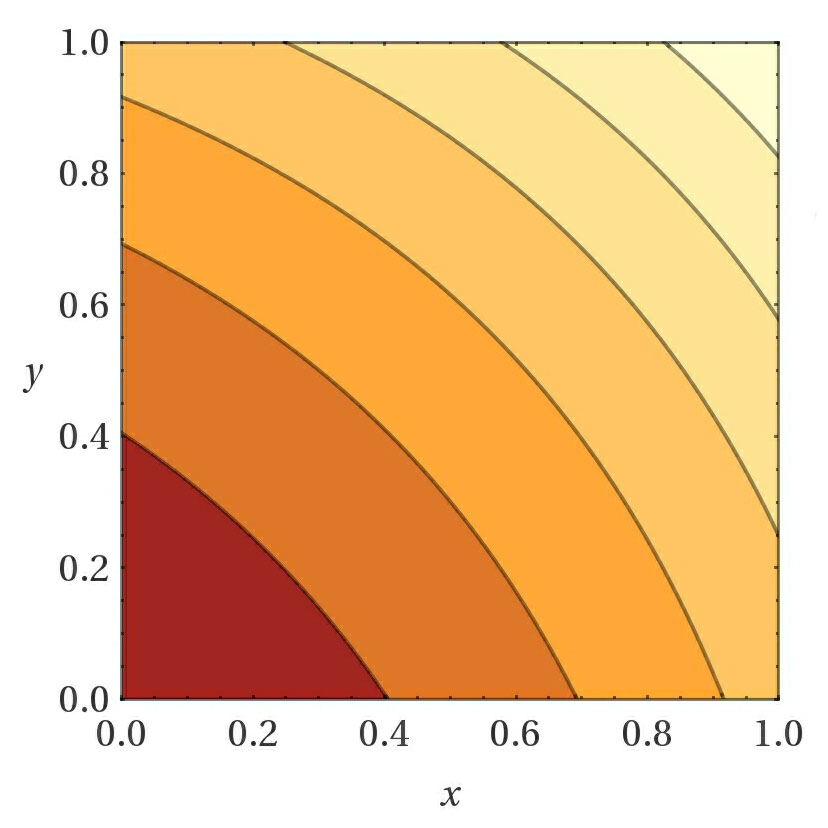
- Take advantage of the adaptive mutation standard deviation (enabled by default). This will adjust the amount of randomness added to mutations based on how learning is progressing. This in turn greatly increases the effective learn rate.
- It's important to start with a balanced set of networks. A randomly initialized chromosome should not have the activation functions pushed to the extremes (ex: 1.0 when using a sigmoid or tanh activation). This can happen when the inputs to the network have high values (absolute value greater than 1.0) and the network is initialized with a normal standard deviation of 1.0. To counter high input values, lower the RandomWeightStandardDeviation value on the GeneticTrainingInfo structure.
Reinforcement Learning
- Reinforcement learning uses agents to capture environment state, actions, and rewards for those actions. The trainers try to improve the network by maximizing the rewards over the course of the game (known as an episode).
- Training by reinforcement learning works best when you run through the same exact scenario many many times. For the best results, the environment should be deterministic & repeatable and should not have random occurances.
- Expect upwards of a million generations in the trainer to converge on a solution.