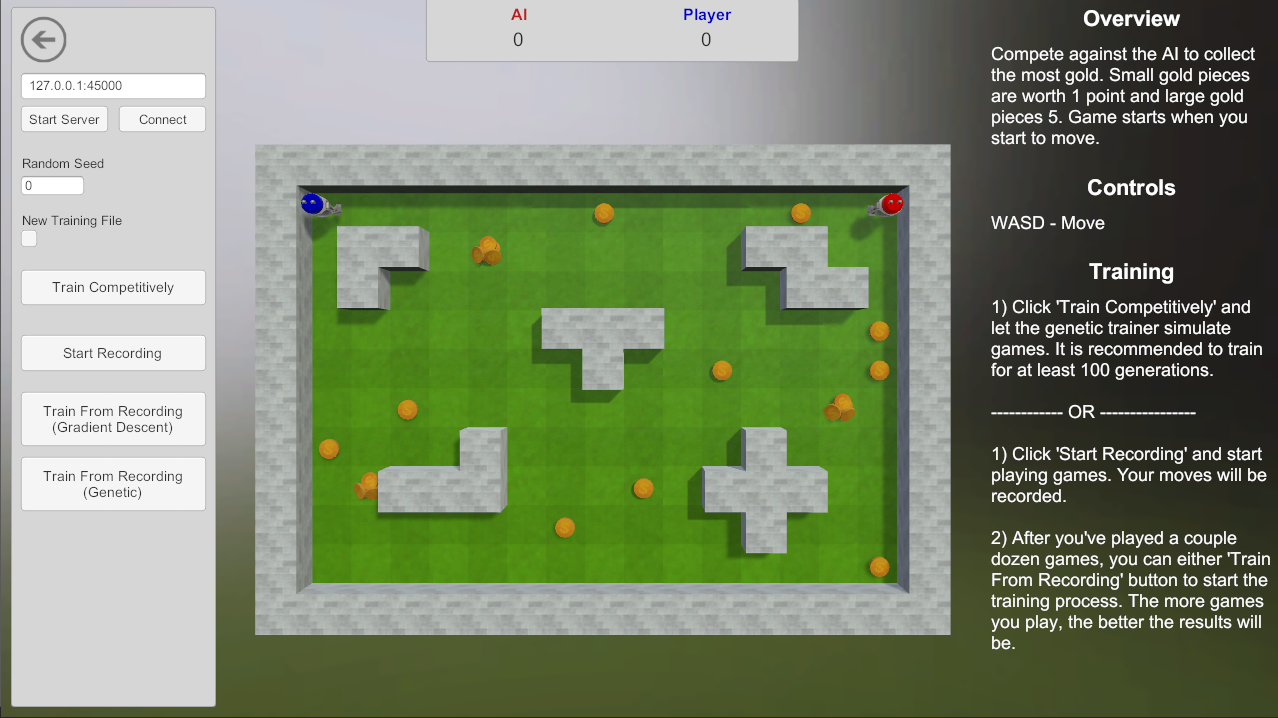
This example game pits you against the computer in a rush to collect the most gold pieces. Gold is randomly scattered across the play grid, with some gold in piles worth 5 gold.
Network Strategy
The neural network in this project needs to take in some form of the board state and output something we can use to move the player. There are many ways this could be established, some working better than others.
The immediate thought is to simply give the network the entire board state and output which direction to move in. The play grid is 15x10 units. There are 5 types of entities: Walls, Human Player, AI Player, Small Gold, and Large Gold. Each entity type for each cell is given a neuron with a value of 1 if it exists at the cell and 0 if not. That gives us a total input dimension of 15x10x5 = 750. If our hidden layer has 32 neurons, that's a total of 750x32 = 24,000 weights. The output layer consists of 4 neurons: one for each movement direction.
While this network can produce interesting results, it suffers from the massive amount of weights. Those weights need data to train - a lot of data. The other big issue is that it's trying to solve two problems at once: targeting the next gold and pathfinding to get there.
One could go a step further and try to simplify the problem into smaller networks that each try to do one thing. First, a network that tries find a target for the player and second, a network that tries to do pathfinding. The targeting network would take in a simplified board state: 2 neurons for the human player (x,y), 2 neurons for the AI player (x,y), one neuron for each gold with a value of either 0, 1, or 5 depending if the gold is there or not. The output can either be a (x,y) location (2 neurons) or one neuron for each cell that represents how much of a target that cell is (15x10 = 150 neurons). The pathfinding network would take as input the target network output along with the character's (x,y) location and walls using the one hot encoding from before.
The new networks have dramatically less weights and can be trained separately using gradient descent. We can take examples from human players as to what gold they go after to train the target network. The pathfinding network can be trained using brute force of every combination of character location and target location. There are again a few problems. Training the pathfinding network independently requires that it have perfect input, which it will not have because the target network does not produce perfect values. The other issue is that while a neural network can learn pathfinding, it will never be as good as a standard A* algorithm.
The solution is to think about the problem differently and to rely on traditional pathfinding for movement. Instead of giving the whole board state and asking for the best target, we are instead going to ask questions about individual gold pieces. Each question comes in the form of a row in the input tensor and each question is independent of each other. The output is a [0..1] value that describes how likely we are to go to that gold. If there are 7 pieces of gold, we run the network with a [7, N] tensor, where N is the input dimension (see below). The output is a [7, 1] tensor. We choose the row that has the highest value and use A* to walk toward the corresponding gold.
Input
The network has an input dimension of 5: the distance from AI to human player's (1), the distance from the AI to this particular gold (1), the distance from the player to this particular gold (1), the value of the gold (1), and the sum value of the gold in a radius surrounding this one (1).
Structure
See SmartEngine/Examples/GoldRush/Resources/GoldTargetGraphDefinition.json
The network consists of one basic hidden linear layer of 16 neurons with selu activation and a linear output layer of 1 neuron with an activation of sigmoid. As mentioned above, the output represents how much we want to go toward this gold.
Like the balance ball example, selu was chosen as the activation of the hidden layer. It is good in general, but especially good with gradient descent when the inputs follow a unit normal distribution. For the output, sigmoid is a natural choice for the output activation function because of its [0..1] range.
Training Methodology
There are two ways to train this network. One is to have the AI compete against itself genetically. The other is to learn from recording a human player. Both are valid and both are available in the example project.
Training competitively uses a Gentic Trainer. With each generation of training, chromosomes play every other chromosome on different maps. If they win, 0 is added to their loss. If they lose, 1 is added. The loss is then averaged across all the games (this step isn't necessary).
Training from recording involves collecting recording data and then training either with a Genetic Trainer or a Gradient Descent Trainer. In both cases, a Loss structure is used. During human play, board state and gold collection is recorded. During the start of training, the board states are read and fed as input. For the output values, a value close to 1 is set if that gold becomes the winning player's next target and a value close to 0 if it is not. Data is compiled and set once. When training using the gradient descent trainer, a stochastic approach is used. See the Tips page for pros and cons of using stochastic vs batch gradient descent training.
Code Structure
See the Balance Ball example for a more detailed description of the network and genetic trainer helper classes
SmartEngine.Examples.GoldRush.GoldTargetNetwork is the network and SmartEngine.Examples.GoldRush.AIController the controller that the AI uses, leveraging the network helper infrastructure.
SmartEngine.Examples.GoldRush.CompetitiveTrainer is the genetic trainer for the competitive version of training. It leverages the networked genetic trainer helper class. Here, each task contains information for two chromosomes since each trial game has two different AI playing at a time. The example is structured in a way that the game can be stepped multiple times in a single Unity frame, allowing for faster than real-time evaluation of the game. It is recommended that you also use this set up when using genetic training in this way.
SmartEngine.Examples.GoldRush.RecordingTrainer trains from a recording using either gradient descent or genetic algorithms. Recording is done by the SmartEngine.Examples.GoldRush.GameRecorder class. A Loss is set up with a buffer containing training output that we gather from the recorded data.